Jose Quesada - A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and cons
PyData Berlin 2016
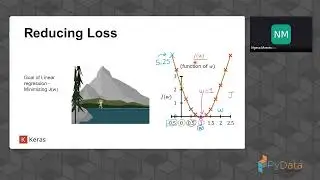
The machine learning libraries in Apache Spark are an impressive piece of software engineering, and are maturing rapidly. What advantages does Spark.ml offer over scikit-learn? At Data Science Retreat we've taken a real-world dataset and worked through the stages of building a predictive model -- exploration, data cleaning, feature engineering, and model fitting; which would you use in production?
The machine learning libraries in Apache Spark are an impressive piece of software engineering, and are maturing rapidly. What advantages does Spark.ml offer over scikit-learn?
At Data Science Retreat we've taken a real-world dataset and worked through the stages of building a predictive model -- exploration, data cleaning, feature engineering, and model fitting -- in several different frameworks. We'll show what it's like to work with native Spark.ml, and compare it to scikit-learn along several dimensions: ease of use, productivity, feature set, and performance.
In some ways Spark.ml is still rather immature, but it also conveys new superpowers to those who know how to use it. 00:00 Welcome!
00:10 Help us add time stamps or captions to this video! See the description for details.
Want to help add timestamps to our YouTube videos to help with discoverability? Find out more here: https://github.com/numfocus/YouTubeVi...
Watch video Jose Quesada - A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and cons online, duration hours minute second in high quality that is uploaded to the channel PyData 01 June 2016. Share the link to the video on social media so that your subscribers and friends will also watch this video. This video clip has been viewed 4,127 times and liked it 33 visitors.