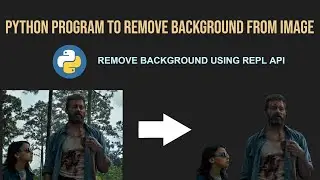
How To Extract Text From PDF Using Python | Python PyPDF2 API | All In One Code
importing required modules
import PyPDF2
creating a pdf file object
pdfFileObj = open('example.pdf', 'rb')
creating a pdf reader object
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
printing number of pages in pdf file
print(pdfReader.numPages)
creating a page object
pageObj = pdfReader.getPage(0)
extracting text from page
print(pageObj.extractText())
closing the pdf file object
pdfFileObj.close()
Watch video How To Extract Text From PDF Using Python | Python PyPDF2 API | All In One Code online, duration hours minute second in high quality that is uploaded to the channel AIOC all in one code 15 September 2020. Share the link to the video on social media so that your subscribers and friends will also watch this video. This video clip has been viewed 605 times and liked it 9 visitors.